Project Showcase
A deep dive into my work, showcasing my technical skills and problem-solving abilities.
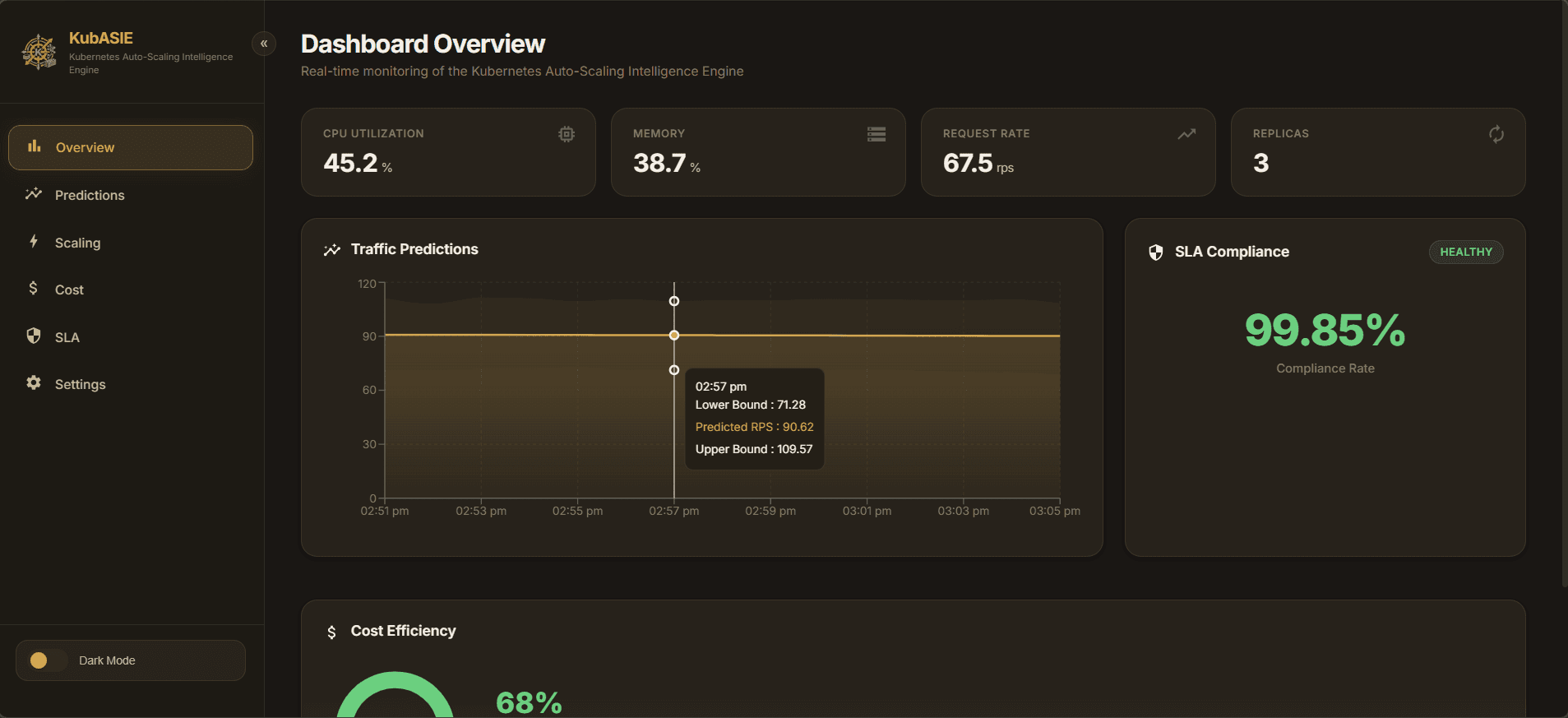
A predictive Kubernetes auto-scaler that dynamically adjusts Horizontal Pod Autoscalers to optimize architecture costs while maintaining SLAs.
The Problem
Kubernetes native HPA only scales reactively resulting in potential latency spikes or over-provisioning during rapid traffic changes.
The Solution
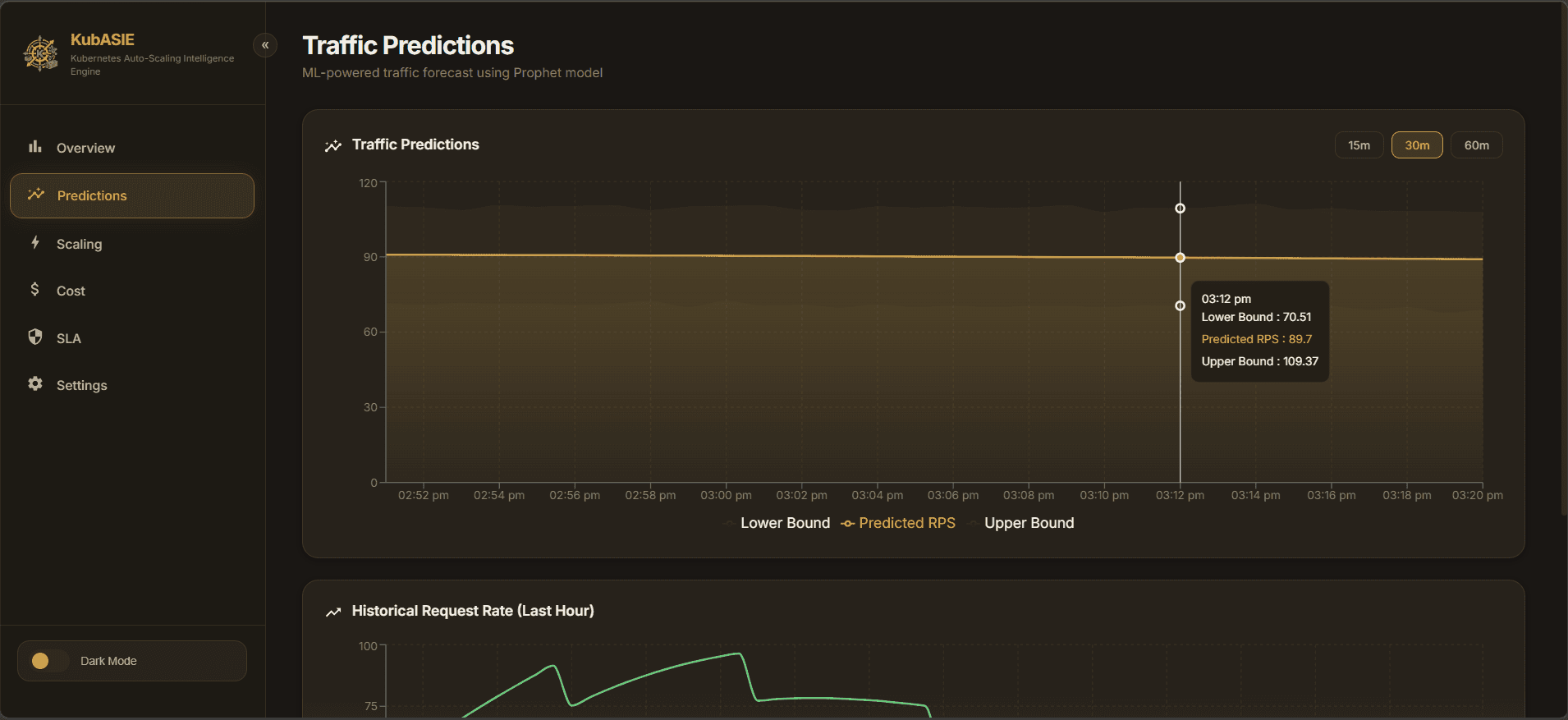
KubASIE implements predictive traffic models using AI algorithms to anticipate load and scale pods proactively, ensuring SLA compliance and cost efficiency.
Key Features
- Predictive traffic models to anticipate cluster load up to 60 minutes ahead.
- Hybrid policy REST API to serve scaling metrics, manual overrides, and predictions.
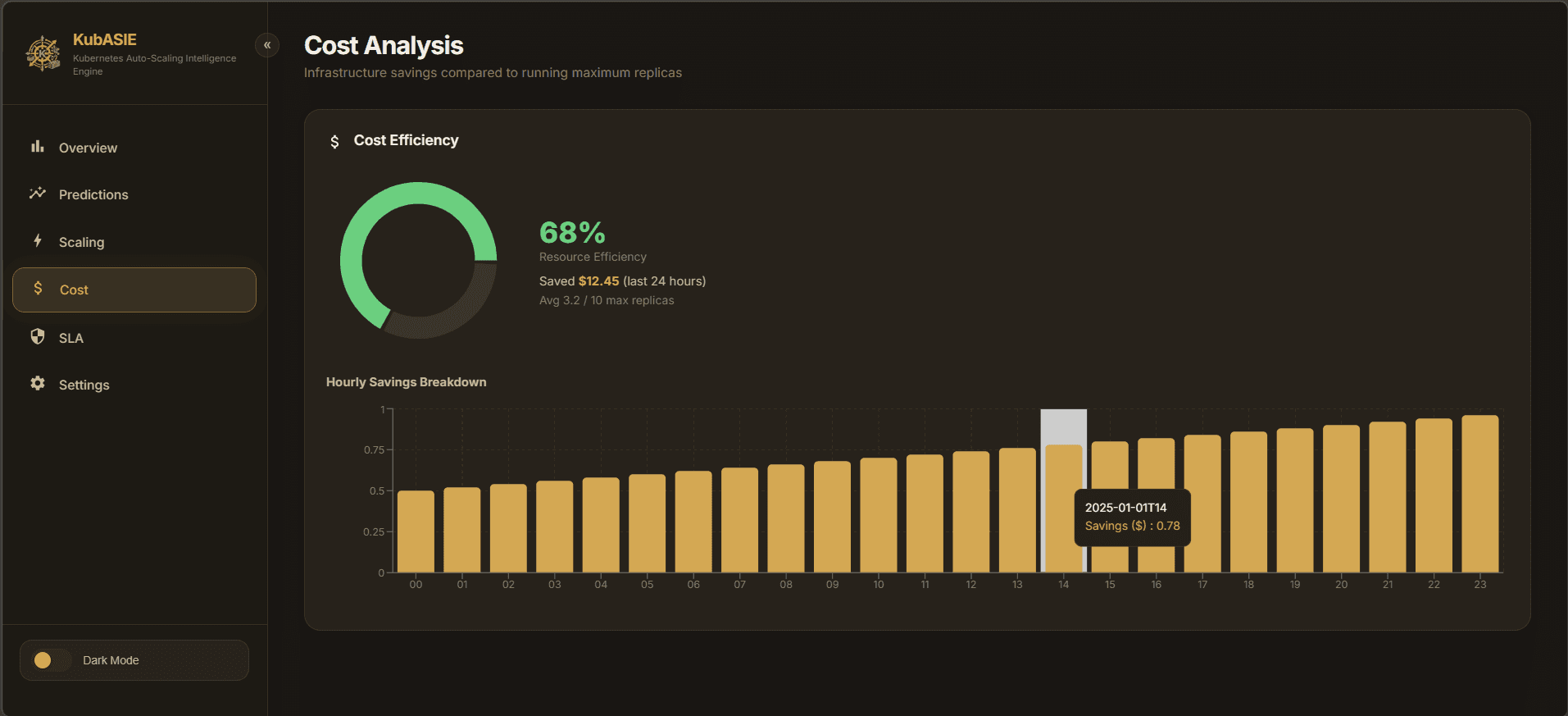
- Observability dashboard to visualize cost savings and Prometheus metrics.
- Containerized and orchestrated the stack using Docker and Helm.
Tech Approach
Trained models (LSTM & Prophet) process metrics and expose scaling policies via a FastAPI REST API. The entire infrastructure is containerized and orchestrated via Docker and Helm.
Results
Optimized architecture costs by reducing over-provisioning while preventing downtime from sudden traffic spikes.